10.中间技术
一、MyBatis
Q:JDBC连接数据库的步骤有哪些?
- 准备JDBC需要的参数,比如username、password、url、driverClass;
- 加载JDBC驱动程序;
- 创建数据库连接;
- 创建Statement;
- 执行SQL语句;
- 遍历结果集;
- 处理异常,关闭JDBC对象资源。
以上是之前用JDBC连接数据库的步骤,而MyBatis内部封装了JDBC,开发时程序员只需要关注SQL语句本身,而不需要花费时间精力去处理加载驱动、创建链接、创建Statement等这些JDBC中非常繁琐的过程。
优点:
- 基于SQL语句编程,相当灵活,SQL语句卸载XML中,解除了SQL与程序代码的耦合,方便统一管理,支持动态SQL;
- 与JDBC相比,减少了代码量,消除了大量冗余代码;
- 能很好地与各种数据库相兼容,只要JDBC支持的数据库MyBatis都支持;
- 提供映射标签,支持对象与数据库的字段关系映射。
缺点:
- SQL语句的编写工作量大,尤其是当字段多、关联表多时;
- SQL语句依赖与数据库,导致不可以随意更换数据库。
1.1 #{}和${}区别是什么?
#{}是占位符,预编译时会处理;${}是拼接符,字符串替换,没有预编译处理。- MyBatis在处理
#{}时,会将sql中的#{}替换为?号;MyBatis在处理${}时,是把${}替换成变量的值。 #{}可以有效防止SQL注入,提高系统安全性;${}不能防止SQL注入。
1.1.1 为什么#{}能有效防止SQL注入?
因为#{}在SQL执行前,会将SQL语句发送给数据库进行编译,在执行的时候,直接使用编译好的SQL语句,替换占位符。因为SQL注入只能对编译过程起作用,所以#{}能很好的避免SQL注入问题。
1.1.2 #{}这么好,那么为什么还要保留${}呢?
如果我们用#{}来编写sql语句,会给对应的变量自动加上单引号’ ‘,比如select * from #{param},最后执行的sql语句是select * from 'user'。
但是如果我们用${}来写sql语句,就不会被加上单引号’ ‘,还是上述的例子,最后执行的是select * from user。
所以,当我们需要拼接的变量不能带单引号的时候,就必须要用${},而其他情况下最好用#{}。
常用${}的情况:
- 当sql中表名是从参数中取的情况;
order by排序语句中,因为order by后面必须要跟字段名,这个字段名不能带引号,如果带引号就会被识别为字符串,而不是字段。
1.2 xml映射文件中有哪些常见的标签?
select、insert、update、delete、resultMap、parameterMap、sql、include、selectKey,再加上动态sql标签。
1.2.1 动态SQL标签有哪些?
if标签:通常用于 WHERE 语句、UPDATE 语句、INSERT 语句中,通过判断参数值来决定是否使用某个查询条件、判断是否更新某一个字段、判断是否插入某个字段的值。foreach标签:主要用于构建 in 条件,可在 sql 中对集合进行迭代。也常用到批量删除、添加等操作中。choose、when、otherwise标签:按顺序判断 when 中的条件出否成立,如果有一个成立,则 choose 结束。当 choose 中所有 when的条件都不满则时,则执行 otherwise 中的 sql。类似于 Java 的 switch 语句,choose 就相当于 switch,when 相当于 case,otherwise 相当于 default。trim、where、set标签:主要是一些辅助功能,用于处理一些条件查询。trim主要用于定制类似 where 标签的功能。where 元素只会在子元素返回任何内容的情况下才插入 WHERE 子句,若子句的开头为 AND或OR,where 元素也会将它们去除。set用于动态包含需要更新的列,忽略其它不更新的列。
1.3 Dao接口的工作原理是什么?
Dao接口的工作原理是JDK动态代理,MyBatis运行的时候会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
最佳实践中,通常一个xml映射文件都会写一个Dao接口与之对应。
Dao接口就是我们常说的Mapper接口,
- 接口的全限名,就是映射文件中的namespace的值;
- 接口的方法名,就是映射文件中MappedStatement的id值;
- 接口方法内的参数,就是传递给sql的参数。
Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement。
比如:com.mabatis3.mappers.StudentDao.findStudentById,可以唯一找到一个namespace为com.mabatis3.mappers.StudentDao下面id=findStudentById的MappedStatement。在MyBatis中,每个<select>、<insert>、<update>、<delete>标签都会被解析为一个MappedStatement对象。
1.3.1 Dao接口里的方法在参数不同时可以重载吗?
Dao接口里的方法可以重载,但是MyBatis的xml里面的ID不允许重复。
1 | /** |
然后在StuMapper.xml中利用MyBatis的动态sql就可以实现。
1 | <select id="getAllStu" resultType="com.pojo.Student"> |
能够正常运行,并得到相应的结果。
MyBatis的Dao接口可以有多个重载方法,但是多个接口对应的映射必须只有一个,否则启动会报错。
1.4 MyBatis是如何进行分页的?分页插件的原理是什么?
- 使用MyBatis提供的RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页;
- 可以在sql内直接书写带有物理分页的参数来完成物理分页的功能,如
offset和limit; - 通过MyBatis中的Interceptor拦截器在select语句执行之前动态拼接分页关键字实现分页。
分页插件的基本原理是使用MyBatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,添加对应的物理分页语句和物理分页参数。
1.5 说一说MyBatis的执行流程
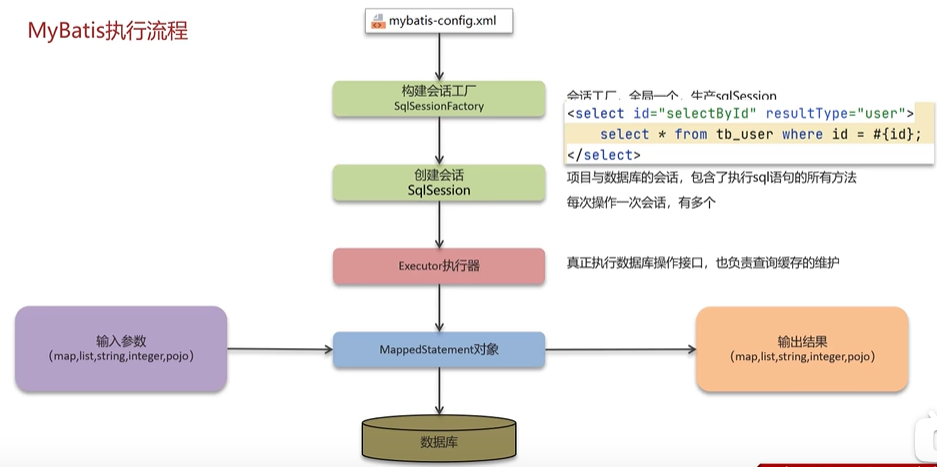
- 读取MyBatis配置文件:mybatis-config.xml加载运行环境和映射文件;
- 构造SqlSessionFactory,一个项目只需要一个,单例的,一般由Spring管理;
- 工厂创建sqlSession对象,这里面就包含了执行SQL语句的所有方法;
- 操作数据库的接口,Executor执行器,同时负责查询缓存的维护;
- Executor接口的执行方法中有个MappedStatement类型的参数,封装了映射信息;
- 输入参数的映射;
- 输出结果的映射;
1.6 Mybatis的延迟加载了解吗?
MyBatis支持延迟加载,即需要用到数据时才进行加载,不用的时候就不加载数据。
延迟加载默认是关闭的,如果需要使用,可以在配置文件中开启lazyLoadingEnabled=true|false。
1.6.1 延迟加载的底层原理
- 使用CGlib创建目标对象的代理对象,这里的目标对象就是开启了延迟加载的mapper;
- 当调用目标方法时,进入拦截器invoke方法,发现目标方法是null值,执行sql查询;
- 获取数据后,调用set方法设置属性值,再继续查询目标方法,就可以查到值。
1.7 MyBatis的一级、二级缓存用过吗?
- 一级缓存:是基于PerpetualCache的HashMap本地缓存,其作用域是sqlSession,当进行flush或close后,该session中的所有缓存都清空,默认打开一级缓存;
- 二级缓存:是基于PerpetualCache的HashMap本地缓存,其作用域是namespace和mapper,可以跨sqlSession,需要单独开启缓存;
注:当某一个作用域进行了增、删、改操作后,默认该作用域下的所有缓存都将被清理。
1.7.1 为什么二级缓存默认不开启?
因为二级缓存是跨sqlSession的,会存在严重的脏读问题,所以默认关闭二级缓存。
二、RabbitMQ
2.1 RabbitMQ如何保证消息不丢失?
- 开启生产者确认机制,确保生产者的消息能到达队列,如果报错可以先记录到日志中,再去修复数据。
- 开启持久化功能,确保消息未消费前,在队列中不会丢失,其中的交换机、队列和消息都要做持久化。
- 开启消费者确认机制为auto,由spring确认消息处理成功后完成ack,也要设置一定的重试次数(一般是3次),如果重试之后仍然没有收到消息,就将失败后的消息投递到异常交换机。
2.2 RabbitMQ消息的重复消费问题如何解决?(如何保证消息的幂等性?)
- 每条消息设置一个唯一的标识id,通过id可以保证消息不会被重复消费;
- 通过幂等方案解决,比如分布式锁或者数据库锁。
2.3 RabbitMQ中死信交换机了解吗?(RabbitMQ的延迟队列了解吗?)
- 医院挂号管理系统中的订单模块就用到了延迟队列去解决超时订单的问题;
- 其中延迟队列其实就是基于死信交换机和TTL(消息存活时间)来实现的;
- 如果消息超时未消费就会变成死信,队列可以绑定一个死信交换机,在发送消息时可以按照要求指定TTL,这样超时未消费的死信就会通过死信交换机进入死信队列中,实现了延迟队列的功能。
2.4 如果有100w条消息堆积在MQ中,如何解决?(如何解决消息堆积的问题?)
- 增加更多的消费者,提高消费的速度;
- 在消费者内开启线程池,加快消息处理速度;
- 扩大队列容积,提高消息堆积的上限;
也可以使用惰性队列来解决,
- 接收到消息后存放在磁盘中,而不是内存;
- 消费者需要消费时,才会从磁盘中读取并加载到内存;
- 支持数百万条消息的存储;
2.5 RabbitMQ的高可用机制有了解过吗?
可以通过镜像队列来实现高可用,其结构式一主多从,所有的操作都是主节点完成,然后同步给镜像节点。
如果主节点宕机后,镜像节点就会替代成为新的主节点。如果在主从同步完成之前主节点就已经宕机,可能会出现数据丢失问题。
2.5.1 出现数据丢失问题怎么解决的?
可以使用仲裁队列,其与镜像队列一样,都是主从模式,支持主从数据同步,是强一致性。而且使用起来非常简单,不需要额外的配置。
2.6 消息队列的模型了解吗?
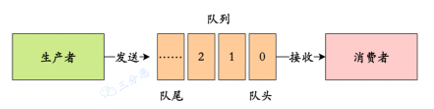
消息队列一共有两种模型:队列模型和发布/订阅模型。
- 队列模型:就是最经典的“发送-存放-接收”模型。生产者往队列里发消息,一个队列可以存储多个生产者的消息,一个队列也可以有多个消费者,但是消费者与消费者之间是竞争关系,一个消息只能被一个消费者消费。
- 发布/订阅模型:消息的发送方被称为发布者,接收方被称为订阅者,存放消息的容器叫主题。发布者将消息发到主题里,订阅者在接受消息之前需要先订阅主题,只有订阅了的订阅者,才能接收到所有消息。
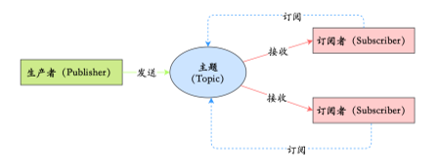
这两种模型的区别是什么?
其实本质上没有什么区别,唯一不同的是:一份消息数据是否可以被多次消费。
2.7 Kafka和RabbitMQ有什么区别呢?
- RabbitMQ用于实时的场景,对可靠性要求比较高的消息传递,而Kafka用于大数据量的处理;
- RabbitMQ有消息确认机制,而Kafka没有消息确认机制;
- RabbitMQ不支持批量操作,吞吐量较小,Kafka内部采用消息的批量处理,消息处理效率高,吞吐量高;
三、设计模式
3.1 工厂模式
在Java中创建对象时,需要用户自己去new对象,这种创建方式会使得该对象耦合严重,加入我们需要更换对象,那么多有new对象的地方都需要修改。
所以可以使用工厂模式来生产对象,而我们直接与工厂交互,彻底和对象解耦,如果需要更换对象,直接在工厂中更换对象即可,从而实现了与对象解耦的目的。
所以说工厂模式最大的优点就是:解耦。
工厂模式包含三种工厂:
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
3.1.1 简单工厂模式
简单工厂模式不是一种设计模式,更像是一种编程习惯。
其中包含三种角色:
- 抽象产品 :定义了产品的规范,描述了产品的主要特性和功能;
- 具体产品 :实现或者继承抽象产品的子类;
- 具体工厂 :提供了创建产品的方法,调用者通过该方法来获取产品。


一旦有了工厂类,就可以在orderCoffee()中直接创建工厂对象,然后调用工厂对象的creatCoffee()方法并且传入参数就能获取对应的coffee了。
这种简单工厂模式虽然解除了Coffee和CoffeeStore之间的耦合,但是CoffeeStore对象和SimpleCoffeeFactory工厂对象之间又新产生了耦合。
后期如果要增加新的咖啡,仍然需要在工厂里面修改代码。
优点:
- 封装了创建对象的过程,可以通过参数直接获取对象;
- 将对象的创建和业务逻辑分开,可以避免修改客户代码;
缺点:
- 新增产品时,仍然需要在工厂类中修改代码,违背了“开闭原则”;
3.1.2 工厂方法模式
定义一个用于创建对象的接口,让子类决定实例化哪个产品类对象;
其中包含四种角色:
- 抽象工厂:提供了创建产品的接口,调用者通过它访问抽象工厂的工厂方法来创建产品;
- 具体工厂:主要是实现抽象工厂中的抽象方法,完成具体产品的创建;
- 抽象产品:描述产品的主要特性和功能;
- 具体产品:实现了抽象产品所定义的接口,由具体工厂来创建。
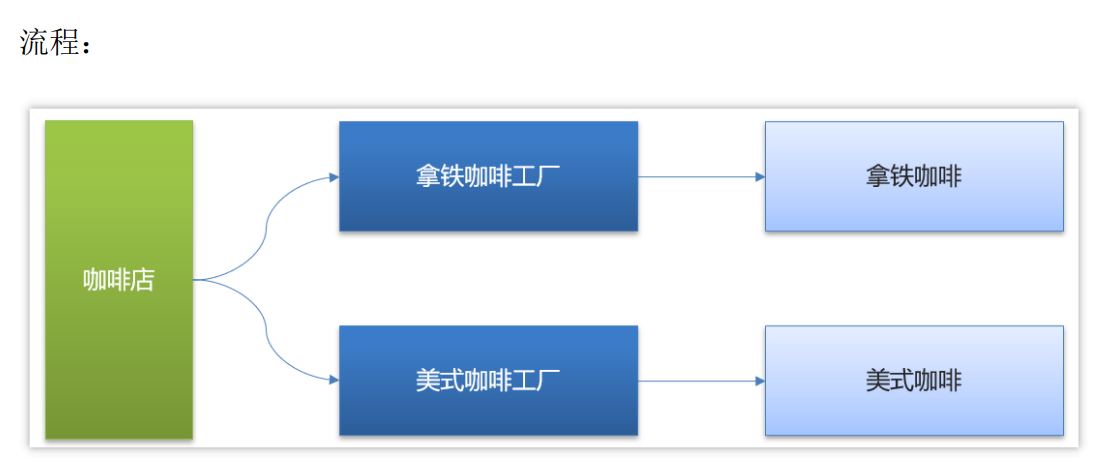
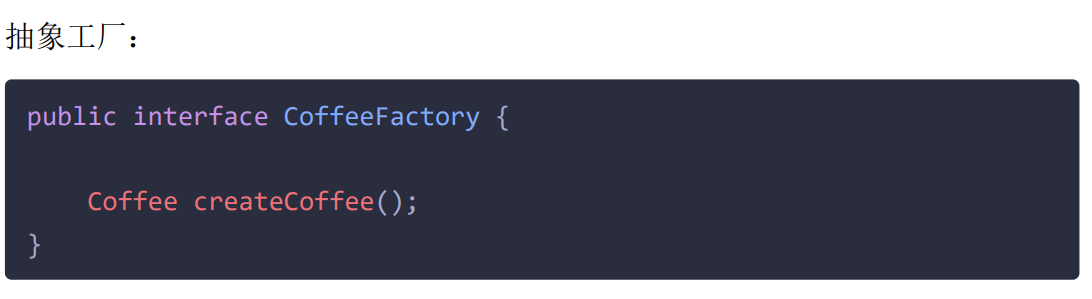


虽然增加产品类时也要增加相应的工厂类,但是不需要修改工厂类的代码了,这样就解决了简单工厂模式的缺点。
工厂方法模式其实就是简单工厂模式的进一步抽象。由于使用了Java中多态的特性,工厂方法模式保持了简单工厂模式的优点,同时解决了它的缺点。
优点:
- 用户只需要知道具体工厂的名称就可得到所要的产品,无须知道产品的具体创建过程;
- 在系统增加新的产品时只需要添加具体产品类和对应的具体工厂类,无须对 原工厂进行任何修改,满足开闭原则;
缺点:
- 每增加一个产品就要增加一个具体产品类和一个对应的具体工厂类,这增加 了系统的复杂度。
3.1.3 抽象工厂模式
抽象工厂模式是工厂方法模式的升级版本,工厂方法模式只生产一个等级的产品,而抽象工厂模式可生产多个等级的产品。
一个超级工厂创建其他工厂,该超级工厂又称为其他工厂的工厂
抽象工厂模式与工厂方法模式一样,主要有四种角色:抽象工厂、具体工厂、抽象产品、具体产品。
加入现在咖啡店要求不仅仅只能点咖啡,还要求能点甜品。如果按照工厂方法模式,需要定义提拉米苏类、抹茶慕斯类、提拉米苏工厂、抹茶慕斯工厂、甜品工厂类,如果再增加其他功能,势必会导致添加的类更多,会发生类爆炸的问题。
所以这里就可以使用抽象工厂模式:
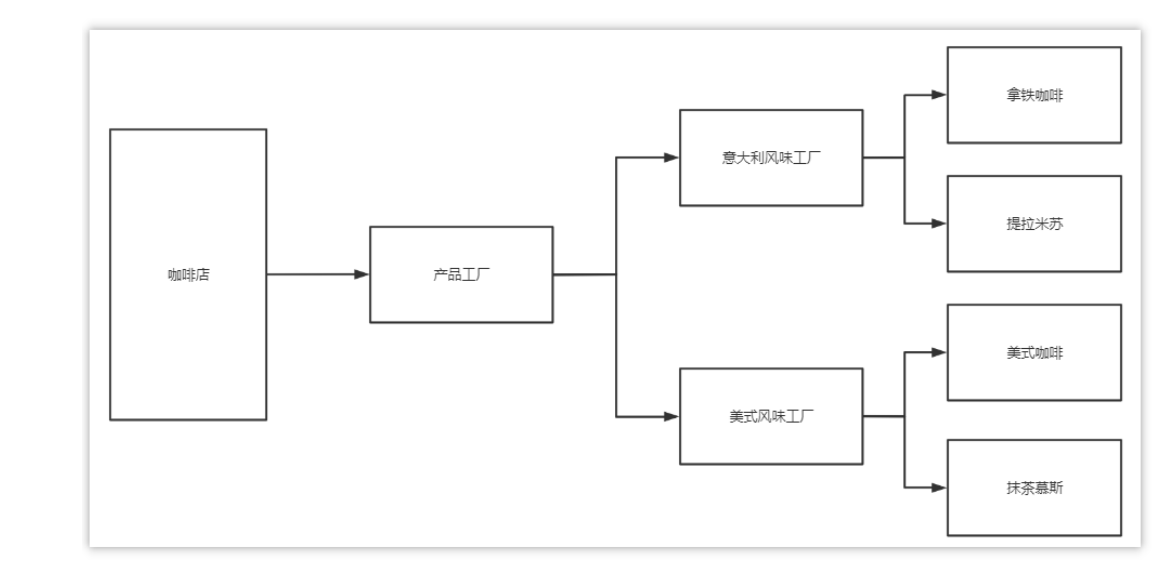
- 优点:当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同 一个产品族中的对象。
- 缺点:当产品族中需要增加一个新的产品时,所有的工厂类都需要进行修改。
使用场景:
- 当需要创建的对象是一系列相互关联或相互依赖的产品族时,比如电器工厂中的电视、洗衣机、冰箱、空调等;
- 系统中有多个产品族,但每次只使用其中的某一族产品,比如有人虽然有很多牌子的衣柜,但只喜欢穿某一个品牌的衣服和鞋;
- 系统中提供了产品的类库,且所有产品的接口相同,客户端不依赖产品实例的创建细节和内部结构。
3.1.4 简单工厂和抽象工厂的区别
抽象工厂相当于抽象了两层,一层抽象层,一层是实现抽象层的具体层,这样后期的扩展和维护会很方便;
简单工厂直接抽取成了一层具体层,完全没有考虑后期的扩展和维护。
3.1.5 工厂方法和抽象工厂的区别
两者最终都是创建对象,但是方法有所不同。
工厂方法采用的是继承,抽象工厂采用的是组合。
抽象工厂中蕴含着许多的工厂方法,所以抽象工厂的相比于工厂方法的另一个优点就是可以把一群相关的产品集合起来(之前提到的各种咖啡,各种甜品等),但是同时也带来了反作用,如果新增一个产品,那么接口将被修改,那是很严重的。所以抽象工厂需要一个很大的接口,因为抽象工厂是创建整个产品家族的,而工厂方法是创建单个产品的,所以说抽象工厂中蕴含着工厂方法。
3.2 策略模式
该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。
策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
比如我们去旅游选择出行模式有很多,可以骑自行车、可以坐汽车、可以坐火车、可以坐飞机等等,最终的目的就是出行,交通工具就相当于是不同的算法,使用哪个算法都可以实现出行的目的。
策略模式主要的角色:
- 抽象策略类:是一个抽象的角色,通常由一个接口或抽象类实现。此角色所给出所有的具体策略类所需的接口;
- 具体策略类:实现了抽象策略定义的接口,提供具体的算法实现或行为;
- 环境类:持有一个策略类的引用,最终给客户端调用。
最经典的例子就是登录问题,对于一个成熟的网站来说,登录方式是有多种的:账号密码登录、QQ登录、微信登录、短信验证码登录等。
所以这里就可以使用策略模式,因为对于用户来说最终的目的是登录网站,至于具体选择哪种登录方式,是用户自身决定的。
抽象策略类:UserGranter

具体的策略类:AccountGranter、SmsGranter、WeChatGranter
1 | /** |
环境类根据用户前端传来的登录类型,选择具体的登录策略。
其实实际开发中场景有很多:
- 支付策略:
- 支付宝支付
- 微信支付
- 银行卡支付
- 促销活动
- 满300打9折
- 满500打8折
- 满1000打7折
- 物流运费
- 5kg以下
- 5kg - 10kg
- 10kg - 20kg
- 20kg以上
一句话总结:只要代码中有冗长的if...else或switch分支判断的代码,都可以采用策略模式进行优化。
3.3 责任链模式
为了避免请求发送者与多个请求处理器耦合在一起,将所有请求的处理者通过前一对象记录其下一个对象的引用,而形成一条链;
当有请求发生时,可将请求沿着这条链传递,知道有对象处理它为止。
比如生活中在学校里我们需要请假,但是批假的人有导师、辅导员、副院长、书记等。不同的领导能批的天数不同,我们必须要根据自己的请假天数去找不同的领导签字。
责任链模式主要包含以下角色:
- 抽象处理者(Handler):定义一个处理请求的接口,包含抽象处理方法和一个后继连接;
- 具体处理者:实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则就将该请求转给它的后继;
- 客户类:创建处理链,并向链头的具体处理者对象提交请求,它并不关心处理的细节和请求的传递过程。
代码实现:
抽象处理者:
1 | /** |
具体处理者:
1 | /** |
客户类:
1 | public class Application { |
优点:
- 降低了对象之间的耦合,降低了发送者和接收者的耦合度;
- 增强了可扩展性,可以根据需要增加新的请求处理类,满足开闭原则;
- 增强了给对象指派职责的灵活性,当工作流程发生变化时,可以动态改变流程顺序;
- 每个类只需要处理自己该处理的工作,不能处理的传给下一个对象,明确了格雷的责任范围;
缺点:
- 对于比较长的责任链,请求的处理可能涉及多个处理对象,性能会受到一定影响;
- 不能保证每一个请求一定被处理,由于一个请求没有明确的接受者,所以不能保证它一定会被处理;
- 责任链建立的合理性要考客户端来保证,增加了客户端的复杂性;
其实责任链模式实际的开发应用有很多:
- 内容审核;
- 订单创建;
- 简易流程审批;
3.4 单例模式
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供了一个全局访问点来访问该实例。
注意:
- 单例类只能有一个实例。
- 单例类必须自己创建自己的唯一实例。
- 单例类必须给所有其他对象提供这一实例。
应用实例:
- 要求生产唯一序列号。
- WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
- 创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
优点:
- 在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。
- 避免对资源的多重占用(比如写文件操作)。
缺点:没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
3.4.1 懒汉式单例
特点:当需要使用对象的时候才进行实例化,需要考虑线程安全的问题,因此要加锁,用时间换空间。
是线程不安全的,不支持多线程。
传统实现:
1 | class Singleton{ |
优化实现:
传统实现方式中,每次获取实例都要被synchronized关键字串行化(即使已经生成了实例)。
而我们加锁的目的是为了防止生成多个实例,因此只需对生成实例的代码加锁,生成实例后,可支持并发访问,提高了性能。
1 | class Singleton { |
由于检查了两次对象是否已实例化,该方法又称“双检锁”,能够同时保证性能及线程安全。
3.4.2 饿汉式单例
特点:类加载时便实例化对象,拿空间换时间。
是线程安全的,但是容易产生垃圾对象。
传统实现:
1 | class Singleton{ |
优化实现:
传统实现方式中,由于类加载时就实例化对象,因此当我们调用静态方法时,也会进行实例化,从而导致空间的浪费。
由于静态内部类中的对象不会默认加载,直到调用了该内部类的方法,因此可用静态内部类封装静态实例变量。
1 | class Singleton{ |
3.4.3 反射可以破坏单例模式吗?为什么?
反射可以破坏单例模式。虽然单例模式的构造器是私有的,单例类外部是不能随便调用的,但是通过反射还是可以获得构造器的访问权。
3.4.4 如何防止反射破坏单例模式?
- 在构造器中做判断,如果对象已经被创建,那么再次创建则不允许创建。但是这种方式有个缺点,如果在常规调用之前就已经使用反射创建,还是不能防止反射破坏单例模式。
- 用枚举单例模式,无法被反射破坏。因为枚举类没有构造器,而且反射的newInstance()方法会判断是否被枚举修饰,如果被修饰,则会创建失败。
3.5 迭代器模式
- 迭代器模式(Iterator Pattern)是常用的设计模式,属于行为型模式;
- 如果我们的集合元素是用不同的方式实现的,有数组,还有Java的集合类,或者还有其他方式,当客户端要遍历这些集合元素的时候就要使用多种遍历方式,而且还会暴露元素的内部结构,可以考虑使用迭代器模式解决;
- 迭代器模式,其实就是提供一种遍历集合元素的统一接口,用一致的方法遍历集合元素,不需要知道集合对象的底层表示,即 :不暴露其内部的结构。
我们最常用的就是遍历集合中的元素,迭代器模式解决了,不同集合(ArrayList,LinkedList)统一遍历问题。
3.5.1 优点
- 提供一个统一的方法遍历对象,用户不用再考虑聚合的类型,使用一种方法就可以遍历对象了;
- 隐藏了聚合的内部结构,用户要遍历聚合的时候只能取到迭代器,而不会知道聚合的具体组成;
- 提供了一种设计思想,就是一个类应该只有一个引起变化的原因(叫做单一职责原则)。在聚合类中,我们把迭代器分开,就是要把管理对象集合和遍历对象集合的责任分开,这样一来集合改变的话,只影响到聚合对象。而如果遍历方式改变的话,只影响到了迭代器;
- 当要展示一组相似对象,或者遍历一组相同对象时使用,适合使用迭代器模式。
3.5.2 缺点
每个聚合对象都要一个迭代器,会生成多个迭代器不好管理类。